
Today's AWS us-east-1 outage affected a significant portion of the tech ecosystem, and the cascading failures we observed through our continuous vendor performance monitoring revealed something important about how concentration risk actually works in modern vendor portfolios.
Most organizations understand infrastructure concentration risk at the surface level. They know which cloud providers host their critical applications and have mapped their direct dependencies on AWS, Azure, or GCP. What today's outage made visible is the concentration risk that lives one layer up in your vendor stack: the SaaS applications your business depends on also make infrastructure choices, and those choices create cascading failures that most TPRM programs don't track.
Our platform monitors thousands of vendors through uptime checks and continuous status page tracking. When AWS us-east-1 started having issues, we saw correlated failures rippling through vendor portfolios across categories that most organizations wouldn't immediately connect to AWS infrastructure.
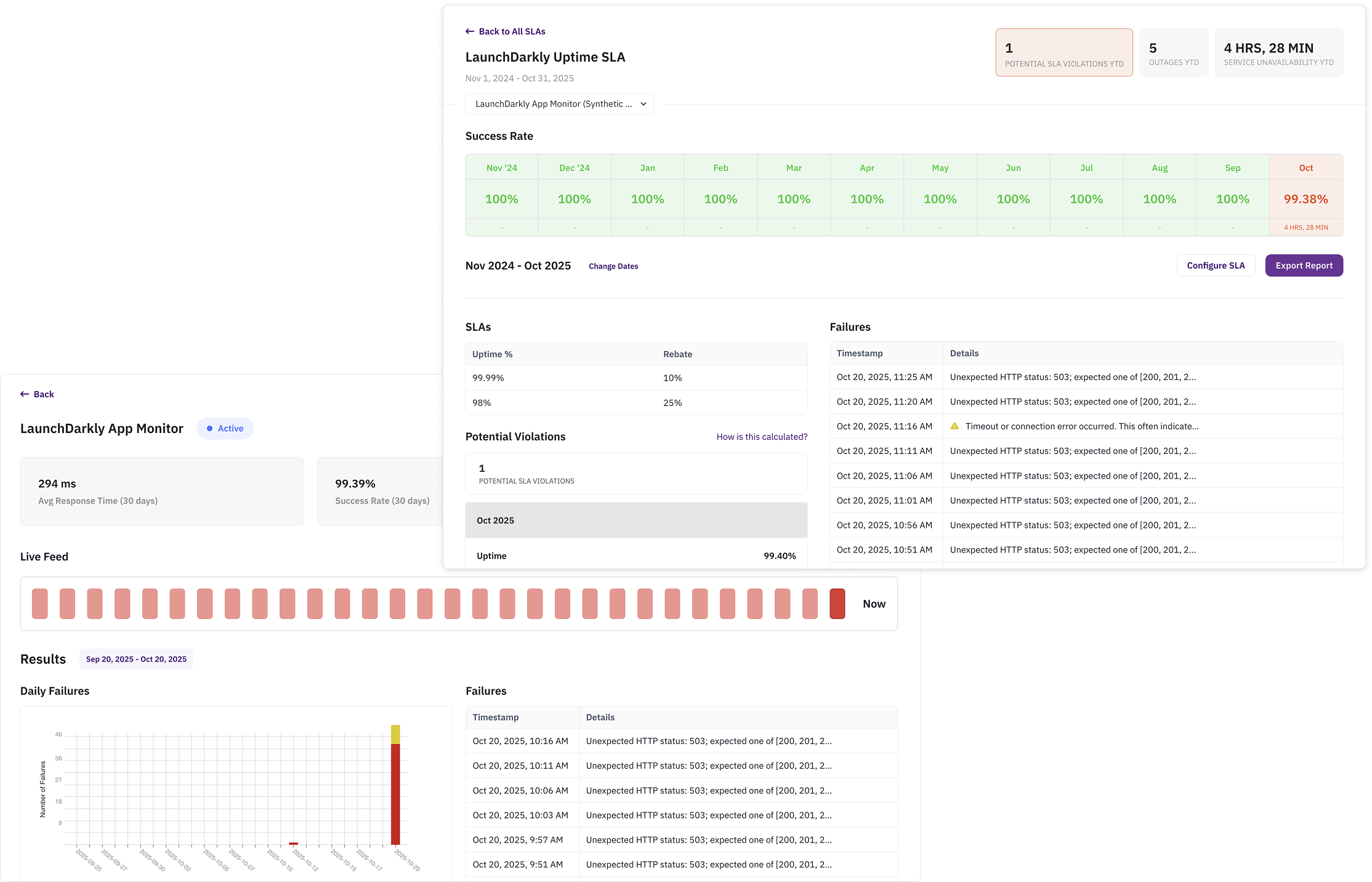
LaunchDarkly started throwing 503 errors, affecting feature flagging and deployment gates for companies relying on it for progressive rollouts. Heap Analytics had outages, disrupting real-time product analytics. Smartsheet went down, affecting project management workflows. Even services that remained technically available experienced severe degradation, with Slack seeing requests take multiple seconds to complete. The pattern continued across Vonage (business communications), Verkada (physical security systems and intercoms), Workiva (financial reporting), 15Five (performance management), Autodesk (design and engineering), CallRail (marketing attribution), Thought Industries (customer education), and many others.
These aren't all infrastructure companies or technical services. They span HR tools, productivity platforms, marketing technology, customer service applications, and business intelligence systems. The common thread wasn't the type of service or business function they supported, but that they all made the same infrastructure choice that most of their customers didn't know about or couldn't easily discover.
What was equally revealing was how different vendors recovered from the same underlying infrastructure issue. Some services were back online within minutes of AWS stabilizing, while others remained degraded for hours afterward. These recovery time differences reveal how effective each vendor's BC/DR planning actually is when tested by real infrastructure failures, not just what their documentation promises.
Business continuity and disaster recovery planning typically treats vendor failures as independent events. You plan for what happens if your payment processor goes down, your CRM has an outage, or your communication platform fails. What's harder to plan for is the scenario where multiple seemingly unrelated vendors fail simultaneously because they share common infrastructure dependencies.
Today's outage created exactly this scenario. Organizations found themselves dealing with degraded or unavailable services across product development, customer support, marketing operations, and internal collaboration tools all at once, not because each vendor independently failed, but because they all relied on the same underlying infrastructure. Your recovery strategies and workarounds often assume that when one vendor fails, you can rely on other systems to handle critical workflows. If those other systems are also affected by the same root cause, your contingency plans break down.
Understanding these hidden concentration risks requires systematic tracking of infrastructure dependencies across your entire vendor portfolio, not just your direct infrastructure providers. Continuous monitoring provides visibility that point-in-time assessments can't offer. When you're tracking vendor availability and status in real-time, you can see correlated failures as they happen and understand patterns in how your vendor portfolio behaves during major infrastructure events.

The goal isn't to eliminate all concentration risk (that's impractical), but to understand where that concentration exists so you can make informed decisions about criticality, workarounds, and recovery priorities. If you know that your feature flagging service, analytics platform, and customer communication tool all depend on AWS us-east-1, you can make different choices about multi-region deployments, alternative vendors for critical functions, or elevated monitoring during infrastructure events.
This also changes vendor selection and contract negotiations. Infrastructure dependencies should be a standard part of vendor due diligence for critical services. You might negotiate for multi-region deployments or require transparency about infrastructure dependencies and disaster recovery capabilities that account for underlying infrastructure failures, not just application-level issues. For existing vendors, quarterly business reviews and contract renegotiations provide the leverage points where you can address infrastructure concentration risk most effectively. Organizations we work with have used these moments to secure better transparency into vendor dependencies, stronger resilience commitments, and in some cases, compensation for outages that revealed gaps between promised and actual performance.
Today's outage demonstrated that the vendors you depend on have made infrastructure choices that affect your operational resilience whether you know about those choices or not. The variance in recovery times also showed which BC/DR plans work under pressure and which only look good on paper. TPRM programs need continuous monitoring to understand infrastructure dependencies and track vendor performance in real-time, catching degradation and cascading failures that point-in-time assessments and vendor-reported metrics can't capture.
Want to know how your vendors handled today's outage? Learn how continuous monitoring tracks real-time performance and recovery, showing you which of your vendors perform under pressure… and which don’t.